Sequences in genes and music share some commonality; namely, both could be represented as linear successions of quantized units. This suggests a possibility to use musical sounds for the annotated display and accompaniment of gene sequence analysis. Using mapping rules assigning a tonal pitch to each one of four bases in DNA and of twenty amino acids in protein, gene sequences were converted to MIDI (Musical Instrument Digital Interface) sequences consisting of MIDI-note data. With MIDI-sequencer programs, the sequences were displayed as piano-roll scores, and played back by multitimbral tone-generator modules. Several exercises were made for comparisons of multiple sequences based on musically recognizable patterns and similarities using a software tool for MIDI-programming.
A simple rule of tonal assignments of DNA bases has been proposed to ease handling, recognition, and remembrance of sequence data (Hayashi and Munakata, 1984). This has been incorporated in some software programs for sequence analysis ("DNA Inspector" for Macintosh and "PC Gene" for IBM personal computers). Such implementations seem intended primarily as divertissement and relaxation. Unfortunately, generally poor sound quality and restricted handling capacity of audio data of personal computers had restrained from the development of potentialities of such assignment.
In late 1980s, easy accessibility of MIDI instruments made it possible to extend and experiment auditory representation of gene sequences further. One natural extension was to assign a different tonal pitch to each one of twenty amino acid residues. Such rules were utilized to convert DNA and protein sequences to MIDI-note sequences, allowing the use of many MIDI-sequencer programs developed for musical productions. This report explores an algorithmic and interactive system of auditory display as applied to gene sequence analysis.
This practice is intended for biologists, students, and laymen without acquaintance of musical theory or MIDI specification. Manuals for MAX (Dobrian and Zicarelli, 1990) and HyperMIDI (Redman, 1990) programs contain useful introductions on the conventions of MIDI data transmissions. Main part of MIDI specification concerned is time-stamped MIDI-note data. They consist of one status byte of note-on channel message and two data bytes of note number and velocity, defining the pitch and loudness of each note, respectively, followed by the same note-off message. The duration of each note is determined by the interval of the note-on and note-off data.
Minimal hardwares are a Macintosh computer connected to a rack-type multitimbral tone generator (hereafter referred to as synthesizers) through a MIDI interface. An input device (such as MIDI keyboards) may be helpful but not mandatory. As software programs, three popular programs were used; HyperMIDI (EarLevel Engineering, CA) working with HyperCard (Apple Computer, Inc., CA) program as a scripting tool to manipulate text and MIDI files, VISION (Opcode System, CA) as a dedicated MIDI-sequencer program, and MAX (Opcode System, CA) as a graphic programming tool. Though former two programs could be replaced by other similar programs, crucial experimentations of this report were realized by the MAX program. It was developed at IRCAM (Institut de Recherche et de Coordination Acoustique/Musique, Paris) since 1986 and made commercially available in 1990. This is a versatile tool for graphic MIDI programming with emphasis and strength on algorithmic composition and real-time interaction.
The tonal assignment of bases in a range of fifth (G=re, C=mi, T=sol, and A=la) has been the simplest and probably the easiest one compared to other proposals using the interval of more than an octave or assigning a range of pitches to each base (Ohno and Ohno, 1986). As for amino acids, after trials of several possible ones, an unobtrusive scale was found that was a simple extension of the one used for bases, stacking up and down the identical pattern of four tones. Twenty pitches from #D1 to B4, covering the approximate pitch ranges of human voices from bass to soprano, were chosen.
Next, twenty amino acids were ordered in a linear array. An unequivocal way to order amino acids from either chemical, biochemical, or genetic properties seemed unattainable. The most popular and useful property seemed hydrophobicity; however, some values of the hydrophobic index are rather arbitrary, and several different indexing schemes have been proposed (Gribskov and Devereux, 1991). Therefore, the hydrophobicity values were combined with other properties to produce common sense groupings. At the end, six groups of amino acids, acidic, basic, polar, small nonpolar, aromatic, and hydrophobic ones (Alberts et al., 1989), were aligned in the ascending order of the scale.
In this system of tonality (Norton, 1984), it was recognized that synthesizer voices tuned to just intonation sound clearer than those tuned to equal temperament, particularly at the high and low ends of the pitches. Therefore, the use of synthesizers with microtuning capability is preferable.
Translating gene sequences to the sequences of MIDI-note events is the basic operation of this practice. It is necessary to convert alphabetical characters representing bases or amino acids in the text files obtainable from sequence databases to MIDI-note numbers according to the assignment rules shown in Table. This could be accomplished by text editors. Here, I used HyperCard and HyperMIDI programs since the use of simple scripts allowed easy and smooth conversions. Using HyperMIDI, it was also possible to write a time-stamped MIDI-sequence file directly from the list of MIDI-note numbers. However, when the sequence was longer than 500 residues, it took quite long time with low-end computers.
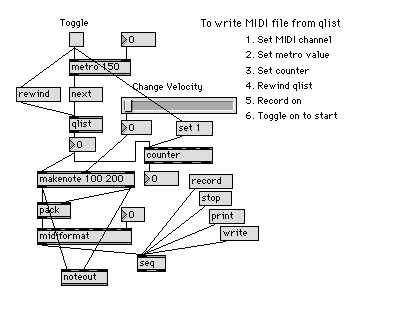
To perform this operation quickly and playfully, a MAX patch shown in Figure 1 was constructed. In the MAX, each program graphically drawn by users and developers is called a patch. Major components of a patch are boxes of object and message connected with lines of cord. In general, each object performs a particular manipulation of the data inputted from the inlet above, and the modified data are outputted from the outlet below.
First, using HyperMIDI or other editors, a semi-colon separated list of MIDI-note numbers (for example, an amino-acid sequence PCRSSCP was converted to 60;67;39;55;55;67;62;) were produced, and this list was pasted to the text window opened by double-clicking the qlist object in the patch.
The metro object, when ban is received from the toggle box above, starts to output a click at the interval defined by the number (in milliseconds) inputted from the upside-right inlet. This click is interpreted by the next message to get out the content of qlist one by one. Since the qlist contains the MIDI-note numbers of the gene sequence, each note corresponding to each residue comes out in succession from the outlet. The number is combined with the value for velocity, which is supplied by the mouse-driven slider object, and the value of duration determined by the argument in the makenote object. This then is formatted by the midiformat object and played out through the midiout box connected to synthesizers. During this playback, the MIDI data are recorded in the seq object as a standard MIDI-sequence file. Moving the slider during this playing session allows to mark musically interesting phrases or biologically meaningful regions by changing the velocity of note-on events.
MIDI-sequence files in the standard format can be opened by MIDI-sequencer programs. Many programs with a variety of sophisticated features of exhibition, edition, and composition are available. An instructive way for this project seems piano-roll display. Musical notes are displayed as filled rectangular bars along the horizontal and vertical axes representing time and pitch, respectively. In the VISION program, when the window of the piano-roll display is placed in front, the lollipop-shaped cursor moves within the score during playback to aid the audio/visual recognition. The score can be viewed at various resolutions of time scale. In Figure 2, two piano-roll displays are shown; in the window above, the entire 4,814 bases of C. elegans fem-3 gene and 388 amino-acid Fem-3 protein in 6 exons (Ahringer et al., 1992) are shown, while in the window below, only a portion of the boundary of an intron and exon 3 is shown.
When multiple sequences are simultaneously played back, each sequence can be assigned to a separate synthesizer voice via different MIDI-channels, and the notes belonging to each channel can be displayed in different color in the score.
Common practice to present results of computer analysis of sequence similarity is to horizontally align sequences with some markings for similar or identical residues (alternate font, style, squared, or colored etc.). Such displays are often confused and uninviting.
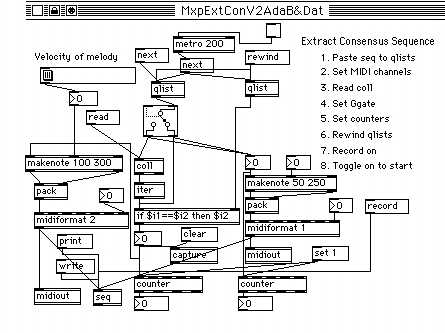
With a MAX patch shown in Figure 3, two sequences are compared and the consensus sequence is extracted as melody. It assumes the user has two sequences aligned without gaps (X in place of deletion). These two sequences are placed into two qlist objects in the central part of the figure by the procedure shown above. The Ggate below the left qlist determines whether the comparison is based on the identity or the similarity defined by the data stored in the coll object below. Various grouping schemes could be stored as separate files and be loaded by invoking the read message to the coll object. The numerical results of the comparison are shown in the number box objects below the counter objects. The noise level of each grouping could be estimated by shifting the frame of the left qlist by invoking the next message.
Two easily recognizable voices, such as plucked string and female choir may be assigned to two sequences. Background voice is fixed at low velocity throughout, while the user can express impression and feeling evoked by the consensus melody by changing the velocity with the slider object. The MIDI sequence file of the performance can be saved, examined, and further embellished with a MIDI-sequencer program.
One fascinating aspect of musical perception is the apprehension of polyphony and counterpoint. When some cues for differentiation are provided (i.e., played by different human voices), it is possible to apprehend two or more independent melodies, which seems to provide an extraordinary pleasure and satisfaction. It is intriguing to explore this capacity of human mind for comparisons of gene sequences.
To make effective display of sequence similarity, two components of musical data, tempo and loudness, may be modulated. This is performed in a MAX patch modified from above involving two qlist objects carrying aligned sequences. A pair of notes coming out from two qlist objects are compared for the identity, and a succeeding expression such as "if left input = right input then output 1.152 else output 0.981" assigns two numbers according to similarity/dissimilarity, which are used to multiply constants to produce new values for metro object and note-on velocity. Thus, both melodies are retarded progressively and become louder when domains of high similarity are encountered. Two sequences are recorded into MIDI-sequence files and played back in a sequencer program with a strip-chart display of velocity, which depicts a similarity profile.
In another MAX patch, two sequences are played back simultaneously, allowing rhythmical interaction by the user through the movement of a mouse-controlled cursor. The aim is to perceive and elucidate interesting dialogs exchanged between two sequences by independently modulating the tempos of each sequence.
For example, fruit-fly gene per product, which is central to the biological clock, exhibits some vestigial sequence similarity to frq gene product of Neurospora crassa (McClung et al., 1989). Recently, the similarity of Per and Sim, product of fruit-fly single-minded gene, has been revealed, which seems to implicate the Per protein in the network of transcriptional regulation (Nambu et al., 1991). Sequence similarities between Per/Sim and Per/Frq pairs are focused on different portions of proteins, and the dialog made by each pair sounds unique.
In this report, a practical approach to employ musical perception and expression for presentations and analyses of gene sequences is pursued with minimal setting available in common households. This is based on the transcription of each unit of bases and amino acids into a musical note. According to the mapping rules presented, gene sequence data are converted to MIDI-sequence data and played back by tone-generating modules.
Two crucial concepts derived from pervasive metaphors of life and music are sequence and motif. Sequence in music originated as a melismatic addition to liturgical chants in medieval churches. This was applied to units of repetitions in melodic or harmonic progressions through baroque and classical area. Current development of digital instruments and computers has lead to the realization and recognition that most aspects of musical activities could be reasonably well approximated as linear sequences of quantized events. Thus, linear successions of quantized information seem to underlie both gene and music giving rise to endless diversities.
The motif in music means a small structural unit of melodic and rhythmic repetition, and takes in various disguises dependent on the styles and genres of music. In motif-finding processes, accumulated data from previous experience seem requisite, which are reactivated and applied to a novel situation posited by the new listening (Minsky, 1989). Also, determination of phrase boundaries is required before trying to find the motif, and this itself is a complex activity of human mind requiring the process of learning and training. In the terminology of interactive music system, both phrase induction and matching is involved for such exercise. It is intriguing to observe that many research projects in computer music are currently addressed to this kind of complex problems (Rowe, 1993).
Searching for the presence of previously identified pattern in new gene sequences is often informative. For this purpose, databases of protein sequence motifs have attained a universal popularity (Bairoch, 1992). However, recent demonstration (Green et al., 1993) that a majority of new sequences derived from eukaryotic cDNAs seem to be devoid of such signature patterns (despite that most of motifs in the current definition seem to have already been catalogued) indicates that more sophisticated strategies of motif-definition and motif-finding need be deployed. This problem might be illuminated from different perspectives and different associations including audio and visual displays, and admittedly preliminary examples in this report will hopefully provoke more imaginative attempts in this direction.
{kind=link}
{kind=link}
{kind=link}